Many people have been asking about the progress of our cloud sync beta – particularly in light of Apple's recent iCloud announcement. We are very excited
about iCloud, but it doesn't change our plans for Things.
iCloud is a great step forward for Apple's desktop and mobile platforms. There is no doubt that users and developers will benefit greatly – it’s easy
for developers to adopt and powerful enough for most tasks. Having said that, there are certain enhancements we hope to bring to Things in the future, which
iCloud in its current form will not support.
In addition, iCloud will be limited to OS X Lion and iOS 5. We know from past experience that it takes a considerable amount of time for many users to migrate
to a new OS. Restricting cloud sync support to Lion and iOS 5 is not an option for us.
Fortunately it is also not necessary, since our own solution has been performing so well in the beta. Everyone who subscribed by the end of last week should
have received an invitation by now, which – to date – means we’ve invited just shy of 20,000 people.
It turns out that the hard work of making our solution scalable has paid off – our sync service has gracefully handled this increasing traffic –
and with usage data on hand from this large group, we can also now confirm that there will be no need to charge for the service. Our cloud sync service will
be free for all users of Things.
Internal testing of our iOS versions is also underway. Our approach to the iOS beta testing will be the same as with Things Mac: we’ll start with a small group
of testers and then scale it up. This will begin on August 22.
If you want to participate in the cloud sync beta, please use the link below.
We're happy to announce that the first round of test pilots have just been admitted to the cloud sync beta pool. As we stated in our last blog post, we're
admitting a small group of testers at first; we'll then proceed with a gradual expansion of the pool as we go.
The new cloud sync architecture has performed exceptionally well in our own internal testing. There is more to the new Things Mac beta than cloud sync however:
we have also significantly changed many data-related aspects of how Things works under the hood. These improvements will go a long way – not only in making
synchronization fast – but in making Things itself faster and more reliable.
One of the main objectives for us in this first round of testing is to eliminate any issues related to these core changes; once satisfied, we’ll quickly proceed
to add more and more test pilots.
If you have not yet received an invitation — please sit tight — and thank you for your patience while we get this underway.
The previous State of Sync posts were fairly technical, at least when compared to other posts that have appeared here in the past. This time, however, I will
concentrate on user-level aspects – and I’ll give a timeframe for our next steps.
After the previous post, our tech support team received quite a few inquiries about what exactly our forthcoming cloud sync solution would entail for end users.
To help answer these questions – at least those we could answer at that time – we published this FAQ page. Today I'd like to
answer some more of your questions – extending and updating that with some new information.
How it will work
As the name already implies, our sync solution is provided as a service that lives in the cloud. This means that the creation of an online account will be
a user’s first necessary step in the configuration of Things for sync.
Of course, Things on the Mac and iOS devices will also need to be updated, in order to enable communication with the cloud server. This software upgrade will
come at no charge, and will also sport a revamped database layer that is not only faster, but specifically optimized for cloud sync usage.
Things will sync frequently. While there will be a way to initiate sync manually there should hardly be any reason for doing so. Every change you make is transmitted
to the cloud almost instantly. No matter when you quit the app, your data is safe with the server already. Whenever you open Things, switch applications,
or wake your computer from sleep, Things will check back with the server to see if there are any updates to pull.
Things will always connect to the server using an encrypted connection. Not only during log-in, as many web sites do, but for every connection. This means
that your to-dos will never be sent in the clear.
Service costs
Without large scale tests, it is not realistic to estimate how much resources our users will consume in the cloud. In particular, the frequency of interactions
between users’ databases and the central service. Therefore we will be doing extensive scalability testing before we make an announcement regarding possible
costs for the service.
Bonjour sync
Some users were asking about the future of our existing Bonjour-based WiFi sync. As a matter of fact, our Bonjour sync – in its current form – is incompatible
with the database layer improvements I mentioned above. As a consequence, there is no way for us to keep the old sync approach with the improved database
layer. What we are planning to do instead, is to rebuild WiFi sync using the same core components that also power our cloud sync technology. We’ll achieve
this by putting a little sync server into Things Mac. This is something that might not ship with the initial release of cloud sync, but shortly thereafter.
Things Mac cloud sync beta
I’m sure the question on the mind of many readers is: when will I be able to play with Things cloud sync first-hand? As it happens, the integration of cloud
sync with the Mac version is a little further ahead of its counterparts on iOS. We have therefore decided to start with a beta of Mac-to-Mac sync first.
Initially, the cloud sync beta will be invite only. Everybody can subscribe, but we will activate accounts on a first come, first served basis as we gradually
scale up the beta. We will be starting with a small number of beta testers at first – the idea is to iron out any kinks on the server early on – we will then
slowly add more people in order to test our system under increasing load. iOS devices will join the fun once we are confident with everything server-side.
When will this happen? We are expecting to start sending out invitation emails on May 2.
But there is one more thing…
The subscription page is already live. If you want to become a test pilot for Mac-to-Mac sync, please sign up here.
We will publish our next sync-related blog post once the beta is ready.
The major new feature of our just-released versions of Things for iOS - Things for iPhone 1.7 and Things for iPad 1.4 - is the ability to create and edit repeating tasks directly on iOS devices. They can also be synced to the Mac version, which is enabled by the new update of Things for Mac.
Designing an interface for repeating tasks is a challenging task for any platform, let alone for small iOS devices. In this blog post I want to give you an
overview of our design goals and the solution we came up with.
Those of you who have been following the development of Things for Mac since it was in beta might remember the challenges we have faced in coming up with a
good UI for repeating tasks for the Mac. We wanted to have a powerful and flexible implementation that was still easy to use. After an extensive design journey with many iterations,
we were very happy and proud of the outcome. Two years later, and after lots of customer feedback, we see that we did most things right. As always, there
is room for improvement – but that’s another chapter.
When we started designing repeating tasks for iOS, we asked ourselves if it was possible to bring the same expressive power to iOS, while still keeping the
UI clean and easy to use. Given the constraints of a small device like the iPhone, we knew that this was not going to be easy.
These were our goals when designing the repeating task UI:
Expressiveness
Repeating tasks come in many different varieties and complexities. If you look at a list of typical repeating tasks people have, you will soon realize that
there is no single prototype recurrence pattern they can all be mapped to. Examples are: "pay rent at the end of each month", "make backups every 2 weeks",
"for the next 5 months, create a performance report at the beginning of the month", "perform health exercises every Monday and Thursday", "prepare for Macworld
Expo every January 1st", "prepare club meeting every second Sunday of the month". A repeating tasks implementation that only has the expressive power to
specify a subset of the tasks above arbitrarily constrains the user in the tasks he can manage efficiently.
Discoverability
The UI should make it obvious to the user what kind of recurrence patterns can be specified. Expressiveness is of little use when users need to read extensive
documentation of how to properly enter certain recurrence patterns.
Ease of use
This goal is obvious, but what exactly does "easy to use" mean in the context of repeating tasks? For regular task entry, one very important aspect of "easy
to use" is that entering a new task requires very few taps. As something that is done over and over each day, any extra taps quickly turn into an annoyance
for the user. This is why our quick entry is designed to keep the number of taps to a minimum. The same does not equally apply to repeating tasks. Typically,
repeating tasks are entered much less frequently. Some are even entered once when you start using the app and remain there for years ("pay rent" is one such
example). So rather than speed of entry, it is much more important that the UI has a great clarity and conciseness when it comes to specifying the different
recurrence patterns.
With these goals as our guides, we evaluated existing implementations, sketched out different designs, discussed the merits and disadvantages of each, and
finally arrived at the version we've now shipped. We believe it is the best and most elegant repeating tasks implementation currently available on iOS. Let
me walk you through it.
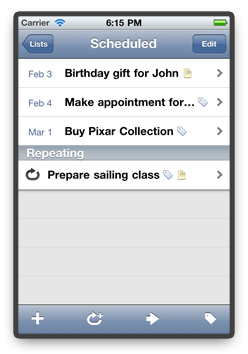
Just like on the Mac version, repeating tasks can be created from within the Scheduled list. For that, we have a new button in the toolbar.
Note how there is one specific place in the UI to go to when you want to create a new repeating task. The existing UI for adding regular tasks is left untouched,
so adding this feature didn't complicate other parts of the application. This is very much in line with the observation that repeating tasks are not entered
frequently.
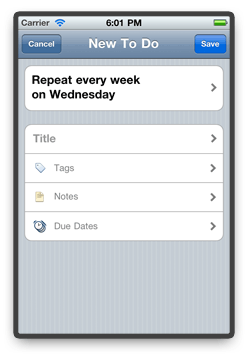
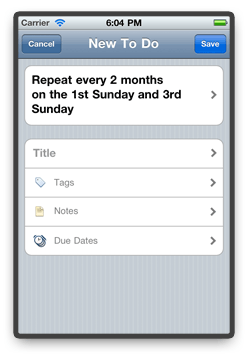
When you tap the button, a new modal view comes up that is specifically designed for repeating tasks.
At the very top, we show an English sentence that describes the current recurrence rule. Below, you can enter the title, tags, and notes of the repeating task, and also specify whether it should create
instances with due dates.
Note that we pre-populate the recurrence rule based on the current day of the week. In most cases, the rule you want to specify probably differs from the one
we show by default. But then why do we show a default rule in the first place?
We believe that it communicates two things very nicely. First, we can present a view that already contains all the elements of a repeating task: the recurrence
rule, together with the title, notes, tags, and due date. So immediately, you know what you are expected to fill out before you can save the task. Secondly,
if you don't like the recurrence rule, you will immediately know that you need to tap the description text in order to change it. And what's really great
about this, even before you see the next UI view with the different controls that let you specify a different rule, you already know what the end
result of those settings will be: a new English sentence that accurately describes the rule you had in mind.
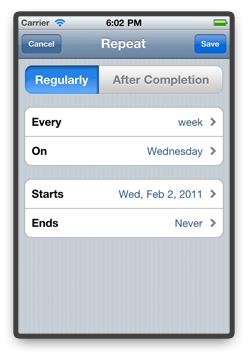
This is the view that appears when you tap the recurrence rule description:
When looking at the general layout of this view, you will realize that – when read from top to bottom – this is basically the same English sentence you saw
before, except it is now divided into different controls that let you specify the different parts of the recurrence rule to suit your needs.
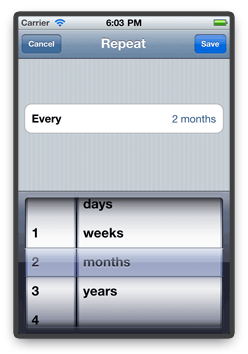
Let's now change this rule to "Every 2 months on the first and third Sunday". First, "Every week" is obviously wrong, so we tap on that. A new view slides
in, letting us specify the "Every 2 months" part.
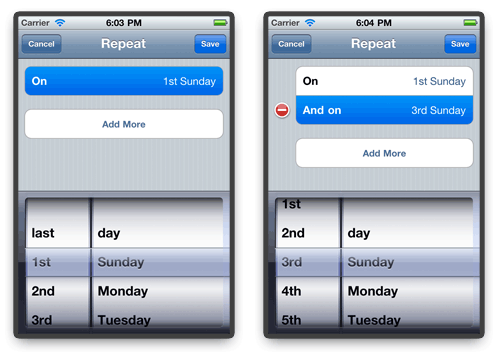
After we're done with that, we go back to the screen before, and tap on the "On" section. In the view that comes up, we select the 1st Sunday, tap on "Add
More", and also select the 3rd Sunday.
Note that we can additionally specify when the recurrence should begin, and when it should end (e.g. after 5 recurrences, or on a specific date), but we won't
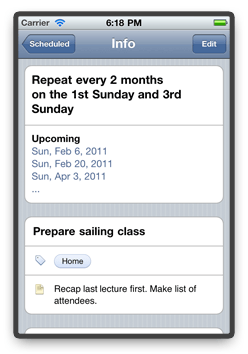
do that for now. Tapping "Save" brings us back to the original screen where the English sentence now properly describes our new recurrence rule.
After we enter the additional repeating task properties and tap “Save”, the new task shows up inside the Scheduled list.
If you later revisit the repeating task, you will conveniently see upcoming recurrences:
This wraps up the walkthrough of the repeating tasks feature. I hope you got a good first impression, but you should definitely try them out on your device
to get a complete picture. There are additional details not covered in this example:
If you specify weekly recurrences, we have an optimized picker that lets you easily select multiple weekdays.
You can also create tasks that repeat after the completion of the previous one.
You can specify the number of times a repetition should occur.
You can pause and resume repeating
tasks (very useful, if you're going on vacation).
If you use Areas, you can assign new repeating tasks directly when you create them.
We hope you enjoy using repeating tasks on iOS. Feedback is, as always, greatly welcome.